You may not realize but you’re likely already aware of structured data. Excel files have a good example of structure.
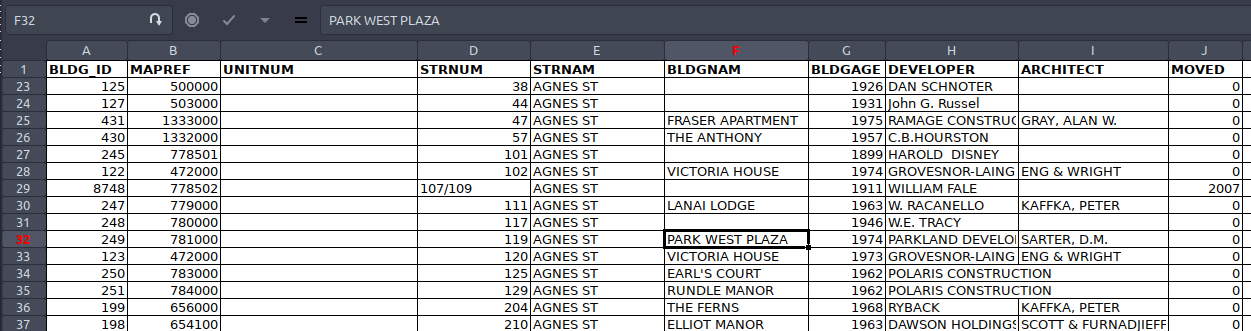
In this screenshot we have an Excel file showing Open Data from the City of New Westminster on building data. It’s pretty easy to understand and you clearly have a unique ID, address, building age, architect, developer, etc.:
Similarly, in this screenshot we have some data from federal government Open Data on procurement contracts. In this case the data is in a structured database table instead of an Excel file but the concept is still the same. You clearly have columns of data for the financial reporting period and the organization that “owns” the contract:

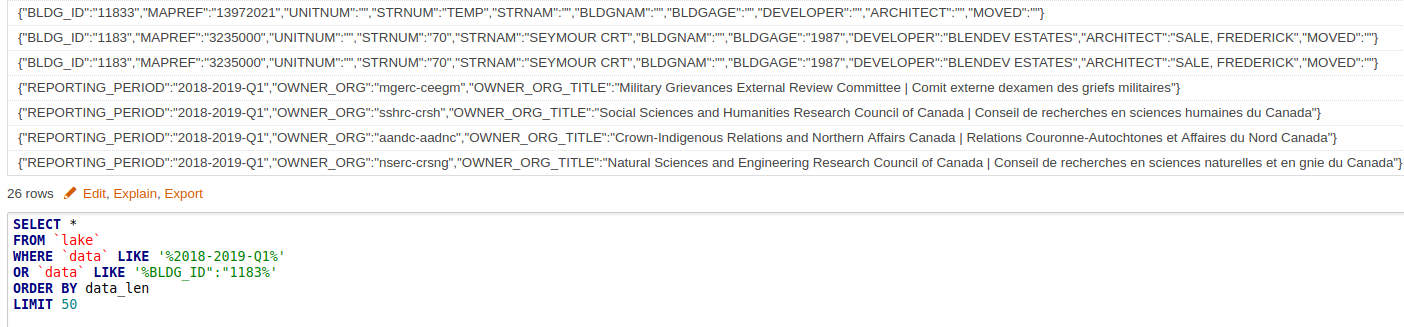
Ok, so at this point we understand that structured Excel data and structured database tables look almost the exact same; rows & columns. Now in the following screenshot we have that federal government contract data but this time it’s unstructured. We have keys (Reporting period) and values (2018-2019-Q1):

Storing the key to identify the data right alongside the data value we can store 2 very different data sources right next to each other in a data lake (instead of a structured data warehouse). In this final screenshot we’re storing municipal building data (BLDG_ID) right next to federal government contract data (REPORTING_PERIOD):
Hopefully that’s a quick, easy intro to the power of a data lake. If you still have questions please comment below or contact us.